On a découvert un Nouveau Code Génétique |
BIOLOGIE MOLECULAIRE |
L'ADN : UN BRIN COMPLEXE
On l'avait identifié deux siècles plus tôt, sans y prêter trop d'attention. L'acide désoxyribonucléique (ADN) semblait bien impliqué dans les mécanismes de l'hérédité, mais personne n'avait la moindre idée de la manière dont cette substance aussi simple pouvait procéder. Nous en étions encore là en 1951, lorsqu'un certain Francis Crick fit la connaissance de James Watson. Deux ans plus tard, ils perçaient ensemble les mystères de la double hélice d'ADN et mettaient en lumière son principe, extraordinairement efficace, de réplication. À compter de ce jour, il ne fit plus de doute à personne que les gènes contenus dans l'ADN commandaient la fabrication des protéines, et de la manière la plus simple et univoque qui soit : un gène = une protéine. Le dogme de la biologie moderne s'imposait. Ainsi, percer les secrets des uns, c'était tout savoir sur les autres. Et le vivant n'allait pas tarder à livrer en bloc ses ultimes secrets. Dans la foulée, les découvertes s'enchaînent. Celle de l'ARN de transfert, puis celle de l'ARN messager. On apprend à isoler les gènes, à effectuer des coupes dans la longue chaîne moléculaire de l'ADN, à en insérer des bribes dans d'autres organismes. En 1990, la biologie voit se succéder la mise en évidence d'un gène du cancer, le premier essai de thérapie génique sur l'homme (même si le résultat restera controversé) et l'annonce conjointe par Bill Clinton et Tony Blair du projet de déchiffrage de l'intégralité du génome humain. Une première ébauche en sera effectivement livrée dix ans plus tard.
Mais le bel enthousiasme qui a prévalu dans la deuxième partie du XXè siècle n'y est déjà plus tout à fait. Les progrès thérapeutiques escomptés ne sont pas au rendez-vous et il se murmure que le dogme en vigueur va devoir être revu ,et corrigé. Ne serait-ce que parce les gènes s'avèrent bien moins nombreux que les protéines qu'ils sont censés déterminer... "L'ADN, un brin décevant" titrions-nous ici même il ya une dizaine d'années. Mais voici qu'à la croisée de l'informatique et de la biologie, des chercheurs viennent d'entrevoir un nouveau code. Caché au coeur de l'ADN, il sera bien plus difficile à déchiffrer. Mais cette fois, il pourrait bien s'agir du code secret de la vie. S&V
 Le patrimoine génétique de toutes les cellules vivantes est inscrit dans leur ADN. Oui, mais comment font-elles pour interpréter ces informations ? Ce mystère, une équipe de chercheurs vient de l'élucider : ils ont décrypté un mystérieux code de la vie. Un exploit qui ouvre sur une nouvelle compréhension de la nature.
Le patrimoine génétique de toutes les cellules vivantes est inscrit dans leur ADN. Oui, mais comment font-elles pour interpréter ces informations ? Ce mystère, une équipe de chercheurs vient de l'élucider : ils ont décrypté un mystérieux code de la vie. Un exploit qui ouvre sur une nouvelle compréhension de la nature.
Imaginez un ouvrage rassemblant toutes vos données personnelles. Imaginez un texte qui soit à la fois le manuel d'instructions pour la construction de vos organes, livres d'histoire du périple de vos ancêtres, les fiches médicales qui prédit quelles maladies pourraient vous menacer. Eh bien, ce mystérieux texte existe : il s'agit de votre ADN, cette molécule enroulée au cour de vos cellules qui concentrent votre patrimoine génétique. Le problème, c'est que la lecture de ce texte ne vous apprendra rien : il est crypté. À l'instar des égyptologues avant Jean-François Champollion, vous vous trouvez en face de signes hiéroglyphiques dans le sens où vous échappe. Que signifie l'information génétique ? Comment est-elle codée ? Comment les cellules réussissent-elles à traduire ce texte en instructions claires et précises pour produire des protéines adéquates au fonctionnement de l'organisme ?
Il aura fallu attendre ces derniers mois pour que ce texte dévoile de nouveaux secrets. Cela grâce à une équipe d'informaticiens de biologistes canadiens de Toronto, dirigée par les professeurs Brendan Frey et Benjamin Blencowe : en mettant au point un algorithme qui mêle plusieurs alphabets biochimiques et des centaines de clés de cryptage différentes, ces chercheurs sont parvenus à faire apparaître plusieurs grandes règles de lecture de cette littérature cryptée.
 TROUVER LA CLÉ UNIVERSELLE
TROUVER LA CLÉ UNIVERSELLE
Ces travaux marquent une date dans l'histoire de la biologie : le craquage du code secret de la vie, vieux de plusieurs milliards d'années, passe à la vitesse supérieure.
Pourtant, les biologistes avaient annoncé avoir découvert le code génétique depuis longtemps. En effet, dès les années 1960, ils avaient mis la main sur le début de l'algorithme qui donne du sens à la séquence génétique. Ce code est on ne peut plus simple. L'ADN est écrit avec les combinaisons de seulement quatre bases et notées A, T, C et G (encadré ci-dessous). Des protéines, la principale matière qui compose nos cellules, sont écrites dans un alphabet différent constitué, lui, de 20 lettres chacune correspondant à un acide aminé. En 1965, les scientifiques réussissent à établir le lien entre ces deux langages : il suffit de grouper les lettres de la séquence d'ADN par trois, chaque combinaison correspondant à un acide aminé particulier à ajouter à la protéine en formation. Et la succession de ces combinaisons, baptisée "gêne", commande la production d'une protéine particulière, via l'enchaînement des acides aminés qui la composent. Grâce à ce fameux code à trois lettres, l'ADN contient les instructions pour fabriquer toutes les protéines. Ce "code génétique" est valable à travers tout le règne du vivant, de la bactérie la plus petite à l'homme en passant par le topinambour. Une clé universelle. Mais il est vite apparu que ce fameux "code génétique" n'autorisait qu'un décryptage fragmentaire. Il n'était qu'une partie d'un code de cryptage bien plus complexe : dans le grand texte de la vie, des pages entières restaient indéchiffrables. Des preuves ? Souvent, surtout chez les organismes complexes, les généticiens se sont avérés incapables de retrouver le texte exact d'ADN à l'origine d'une protéine. Inversement, en considérant une séquence d'ADN, ils n'arrivaient pas tou jours à en déduire les protéines produites avec.
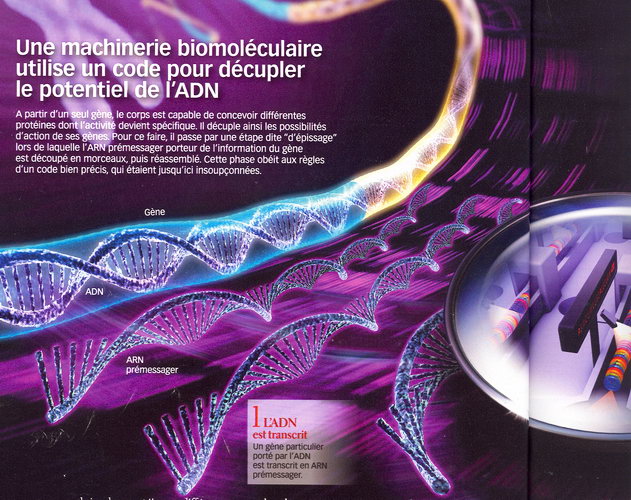
LES MOTS DE LA GÉNÉTIQUE Au cour de nos cellules, dans leur noyau, est empaquetée en chromosomes une longue molécule en forme de double hélice : l'ADN (acide désoxyribonucléique), le support de notre patrimoine génétique. L'ADN consiste en une enfilade de composés chimiques, les bases (plus de 3 milliards chez l'homme), dont l'ordre (la séquence) a été dévoilé en 2001. Elles sont quatre : l'adénine (A), la thymine (T), la cytosine (C) et la guanine (G). L'ADN contient plusieurs types d'informations utilisées par la cellule pour réguler son activité et produire d'autres molécules, les protéines. Ces dernières constituent l'essentiel de la matière des cellules et de ses moyens d'action. Elles sont un assemblage réalisé à partir de 20 acides aminés (composés chimiques en partie synthétisés par la cellule elle-même) et les données qui permettent leur assemblage se trouvent sur certaines portions de l'ADN, appelées gènes. Elles ne sont toutefois pas formées directement à partir des gènes, mais via des ARN (acides ribonucléiques) qui en sont les copies éphémères. ARN et ADN sont écrits dans le même alphabet, seule la thymine est, dans l'ARN, remplacée par l'uracile. L'ADN est donc transcrit en ARN, qui est alors traduit en protéines. |
ISOLER LE CHAÎNON MANQUANT
Entre l'ADN et les protéines se cachait donc un autre code qui expliquerait pourquoi, alors que l'ADN ne contient qu'une vingtaine de milliers de gènes, nos cellules en tirent les instructions pour fabriquer des centaines de milliers de protéines différentes.
À ce stade, une seule certitude : ce mystérieux code intervient dans les relations qui se tissent entre trois acteurs principaux : l'ADN, les protéines et... les ARN. Les ARN ? Il s'agit de sortes d'intermédiaires entre l'ADN et les protéines. Plus précisément, les ARN sont des copies de certaines portions de l'ADN, correspondant le plus souvent aux gènes, et c'est avec ces copies que travaille la cellule. Comme ça, elle n'a pas besoin de découper le document original contenu dans l'ADN. Ces ARN sont donc les "messagers" de l'ADN. On les appelle d'ailleurs des ARN messagers. Or, ces messagers jouent un rôle crucial, comme l'ont découvert peu à peu les biologistes dans les années 1980 : si l'on ne parvient pas à retrouver directement la séquence d'ADN à partir de "sa" protéine, et vice versa, c'est de leur faute. Car à partir d'une même séquence d'ADN, la cellule ne produit pas un, mais jusqu'à plusieurs milliers d'ARN messagers différents : elle découpe en effet le messager initial, la première copie du texte de l'ADN, en fragments plus ou moins longs, elle en détruit certains (introns), en raboute d'autres entre eux (exons)... et ce ne sont pas tou jours les mêmes exons qui sont raboutés. Que deviennent les innombrables messagers issus de ce mécanisme appelé "épissage alternatif" ? Simple : chacun va coder pour une protéine distincte. Oui, mais comment la cellule choisit-elle d'épisser un ARN d'une façon plutôt que d'une autre ? Quelles règles lui dictent l'épissage qui convient dans telle circonstance à tel moment ?
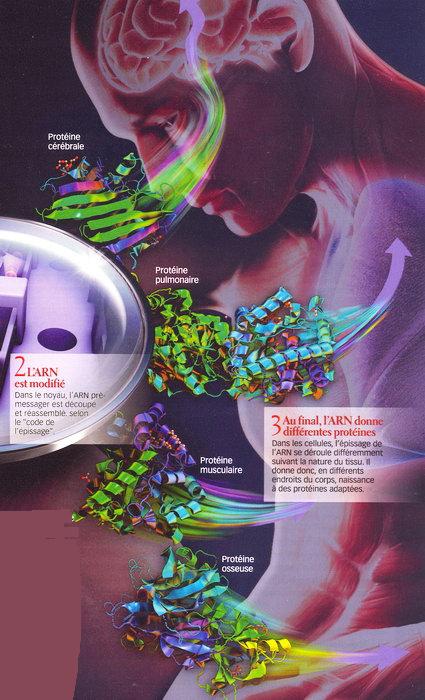
CODE DE L'ÉPISSAGE : voici comment un ARN produit trois protéines différentes. Comment un gène peut-il donner plusieurs protéines différentes selon qu'il est exprimé dans une cellule cérébrale, musculaire ou osseuse ? La réponse se trouve à mi-chemin entre le gène et la protéine finale quand l'information génétique est transportée par l'ARN messager soit une suite de composés chimiques (bases), désignés par les lettres A, U, C et G. 1/ Un gène est transcrit en ARN ; À partir de l'ADN, un gène vient juste d'être copié en ARN prémessager dans le noyau de la cellule. Cet ARN est constitué d'exons (séquences utiles à la fabrication des protéines) et d'introns (séquences porteuses d'instructions de découpage de l'ARN). Dans les introns, l'agencement des bases forme des "instructions" qui guident l'épissage de l'ARN : suppression des introns et choix des exons à conserver. 2/ Cet ARN prémessager est décodé ; Dans chaque tissu (ici : cérébral, musculaire et osseux), la cellule reconnaît, dans la séquence d'un premier intron, des "mots de code" (AG, CU, GCAUG, etc.) qui, selon le tissu, conduisent à la conservation ou à la suppression de l'exon suivant. 3/ L'ARN messager se constitue ; Intron après intron l'ARN est décodé. Les exons conservés sont raboutés entre eux. Ils forment ensemble une séquence différente d'un tissu à l'autre. 4/ Il se forme trois ARN messagers ; Dans chaque tissu, l'ARN prémessager de départ a donné naissance à des ARN messagers spécifiques de chaque tissu. Ils seront ensuite traduits en une protéine. |
À ces questions, les Canadiens apportent de nouveaux indices. "L'épissage alternatif, confirme Hugues Roest Crollius, de l'Institut de biologie de l'Ecole normale supérieure, on le connaît depuis près de vingt ans, mais on en mesure seulement depuis peu l'étendue. Comprendre comment ce mécanisme est régulé devient donc un challenge majeur. "D'autant plus qu'en 2008, une publication a révélé que près de 95 % de nos gènes sont concernés par l'épissage... On comprend dès lors pourquoi les travaux de l'équipe de Toronto sont appelés à faire date. Et Brendan Frey en est bien conscient : "Ces dix dernières années, raconte le bio-informaticien canadien, plusieurs groupes de recherche, dont le mien, ont montré que ce mécanisme générait une diversité de messages génétiques beaucoup plus grande qu'on ne le soupçonnait. J'ai décidé en 2002 de répondre à cette question : 'qu'est-ce qui, dans le code génétique, détermine comment ces divers messagers sont générés' ?" Mission accomplie ! Pour réaliser cette prouesse, l'équipe canadienne s'est focalisée sur quatre tissus de la souris : nerveux, musculaire, digestif et embryonnaire.
Son idée ? Compiler dix ans d'informations accumulées sur l'épissage qui n'avaient jamais été mises en relation à cette échelle. Car un peu partout dans le monde, d'autres équipes s'étaient penchées sur certains gènes, et avaient repéré des séquences qui semblaient jouer un rôle dans les opérations, mais aucune loi générale ne se dégageait. "Nous avons infecté dans nos ordinateurs des milliers de ces exemples d'épissage connus pour les quatre types de tissus considérés ainsi que  toutes les séquences des ARN concernés", détaille Brendan Frey. L'équipe partait du fait que la cellule trouve ses instructions d'épissage dans les ARN eux-mêmes. C'est donc dans la séquence des ARN, avant qu'ils ne soient épissés, que des "mots de code" indiqueraient à la machinerie cellulaire où elle doit couper, quels fragments garder, ou non, dans le message final. "Ce décryptage se résume à repérer des 'mots' le long de la séquence d'ARN et mettre une signification dessus", explique Hugues Roest Crollius. Et aux rares mots de code déjà connus sont venues s'en ajouter des cohortes de nouveaux ! Rien que pour les quatre tissus considérés, il y en avait des milliers. Lesquels interagissent ensemble - et de façon différente selon le type cellulaire où ils se trouvent ! Ce qui engendre un niveau de complexité inextricable !
toutes les séquences des ARN concernés", détaille Brendan Frey. L'équipe partait du fait que la cellule trouve ses instructions d'épissage dans les ARN eux-mêmes. C'est donc dans la séquence des ARN, avant qu'ils ne soient épissés, que des "mots de code" indiqueraient à la machinerie cellulaire où elle doit couper, quels fragments garder, ou non, dans le message final. "Ce décryptage se résume à repérer des 'mots' le long de la séquence d'ARN et mettre une signification dessus", explique Hugues Roest Crollius. Et aux rares mots de code déjà connus sont venues s'en ajouter des cohortes de nouveaux ! Rien que pour les quatre tissus considérés, il y en avait des milliers. Lesquels interagissent ensemble - et de façon différente selon le type cellulaire où ils se trouvent ! Ce qui engendre un niveau de complexité inextricable !
Comment démêler cet écheveau et dégager les règles derrière ce formidable moteur de diversité qu'est l'épissage alternatif ? C'est ici que la théorie de l'information et la puissance de calcul de l'informatique entrent en jeu. "Nous avons mis au point un algorithme qui a été capable d'identifier quels mots de code fonctionnent ensemble, et de quelle façon. Ce nouveau 'code de l'épissage' peut ainsi être utilisé pour prédire où, selon les tissus, vont se faire les coupures dans les messages", détaille Brendan Frey. Le voici donc enfin, ce nouveau code de la vie, celui qui permet à la cellule de savoir comment épisser les ARN selon son rôle dans l'organisme. C'est grâce à lui que les cellules se distinguent les unes des autres et ajustent leurs comportements aux circonstances. C'est aussi à cause de mauvaises interprétations de ce code qu'elles tombent parfois malades.
L'HOMME BIENTÔT DÉCRYPTÉ
Les chercheurs ont aussitôt mis en ligne leur machine à décrypter afin d'aider les confrères du monde entier dans leurs investigations génétiques. Car elle apporte un nouveau regard sur la façon dont les organismes ont pu "acquérir leur incroyable diversité, mais aussi, un formidable outil pour étudier les conséquences des dérapages de ce mécanisme délicat.
L'équipe canadienne sait qu'elle n'en est qu'au début de son long et ingrat travail de décryptage... Après avoir travaillé sur la souris, il lui faudra transposer ses résultats chez d'autres espèces. "Nous sommes en train d'avancer sur l'humain, annonce Brendan Frey, et nous espérons fournir une première version au printemps 2011". En attendant, malgré les bons résultats de leur outil de décodage sur le rongeur, "ils ne peuvent prédire avec certitude que 60 % des événements d'épissage alternatif. Cela montre qu'il manque encore des mots de code pour arriver aux 100 %", remarque Joëlle Marie, biologiste moléculaire spécialiste de l'épissage au Centre de génétique moléculaire de Gif-sur-Yvette. Combien y en aura-t-il au final ? Personne ne peut le dire. Existe-t-il d'autres niveaux de codages encore insoupçonnés ? Sûrement. La vie a eu plusieurs milliards d'années pour complexifier son précieux code génétique et engendrer des millions d'espèces. Chaque nouveau secret percé par ces généticiens dévoile tout un pan de la vie parfois à peine envisagé. C'est le cas avec l'épissage altematif qui révèle que des séquences d'ADN non traduites en protéine ont leur importance. Quelles surprises réservent alors les 98 % de l'ADN qui ne semblent porter aucun gène ? Tel est le prochain niveau de cryptage que les généticiens devront encore craquer.
 UN CODE POUR COMPRENDRE LA DIVERSITÉ BIOLOGIQUE
UN CODE POUR COMPRENDRE LA DIVERSITÉ BIOLOGIQUE
Qu'elles soient osseuses, du foie, du cerveau, des muscles, toutes les cellules d'un même individu ont beau être différentes, elles disposent du même code génétique. Un ADN commun et pourtant plus de 200 types cellulaires de notre corps... Comment imaginer qu'une cellule de muscle, de fois ou un neurone - que tout sépare, de leur fonction à leur apparence - disposent des mêmes informations ? "L'épissage alternatif explique en bonne partie ces variations, indique Joëlle Marie, directrice de recherche à l'Inserm. Il est un des moyens utilisés par les organismes supérieurs pour augmenter leur diversité, puisque les combinaisons variables des fragments de messages génétiques produisent des protéines différentes". Comme les instruments d'un orchestre savent quelle section de la partition jouer, nos cellules n'expriment que la fraction de la partition génétique qui les concernent et elles la jouent selon leurs règles - dont le décodage est engagé. "Mieux connaître le code aidera à mettre en lumière un savoir fondamental concernant la manière dont notre corps fonctionne, et à prédire les mécanismes de régulation qui entre en jeu selon les tissus", explique Brendan Frey. 95 % de nos gènes étant concernés par l'épissage, "on connaît près de 150.000 messages génétiques issus de seulement 22.000 gènes, pose Hugues Roest Crollius, de l'institut de biologie de l'école normale supérieure. Un gène génère donc en moyenne huit messages". Certains enfants au moins, comme celui de la globine (une protéine de l'hémoglobine), et d'autres plus. Le tissu nerveux, l'un des plus complexes, semble être celui qui a le plus recours : les gènes codant pour les protéines nerexines peuvent chacun donnait des milliers de messagers différents.

 UN CODE POUR DÉCRYPTER L'ÉVOLUTION DE LA VIE
UN CODE POUR DÉCRYPTER L'ÉVOLUTION DE LA VIE
 Nématode, mouche verte, bactéries, levure ou souris : plus un animal est complexe, plus il utilisera l'épissage. Les chiffres sont parfois embarrassants ! Ainsi, l'être humain ne possède guère plus de gènes que le vers Caenorhabditis elegans (moins de 22.000 contre 19.000 gènes). Mais depuis la découverte de l'épissage alternatif, on sait que la complexité d'un organisme ne se mesure pas à son nombre de gènes, comme on a pu le croire. En fait, plus un animal est complexe, plus il a recours à l'épissage, ce qui lui permet, dans une cellule donnée et pour un gène précis, de mettre à l'épreuve de la sélection naturelle différents messagers génétiques. Chez les animaux unicellulaires, ce mécanisme est quasi inexistant : les bactéries ne le connaissent pas et on peut compter sur les doigts d'une main les gènes épissés chez la levure. Chez des animaux pluricellulaires comme le ver et la mouche, l'épissage alternatif est encore anecdotique - même si la mouche possède le jeune champion de l'épissage alternatif : Dscam, qui, dans le système nerveux, peut engendrer 38.000 messages différents ! Ce sont les mammifères qui exploitent le mieux cette formidable machine à créer de la diversité. Chez l'homme, 95 % des jeunes sont épissés. Ce mécanisme semblant avoir accompagné l'évolution de la vie animale, le décrypter pourrait révéler comment l'homme a pu acquérir sa complexité. "Nous étudions les variations entre les codes de l'épissage de la souris et de l'homme : certaines pourraient expliquer les différences de sophistication d'organes aussi importants que le cerveau", prévoit le professeur Brendan Frey, chef de l'équipe canadienne décrypteuse du code de l'épissage alternatif.
Nématode, mouche verte, bactéries, levure ou souris : plus un animal est complexe, plus il utilisera l'épissage. Les chiffres sont parfois embarrassants ! Ainsi, l'être humain ne possède guère plus de gènes que le vers Caenorhabditis elegans (moins de 22.000 contre 19.000 gènes). Mais depuis la découverte de l'épissage alternatif, on sait que la complexité d'un organisme ne se mesure pas à son nombre de gènes, comme on a pu le croire. En fait, plus un animal est complexe, plus il a recours à l'épissage, ce qui lui permet, dans une cellule donnée et pour un gène précis, de mettre à l'épreuve de la sélection naturelle différents messagers génétiques. Chez les animaux unicellulaires, ce mécanisme est quasi inexistant : les bactéries ne le connaissent pas et on peut compter sur les doigts d'une main les gènes épissés chez la levure. Chez des animaux pluricellulaires comme le ver et la mouche, l'épissage alternatif est encore anecdotique - même si la mouche possède le jeune champion de l'épissage alternatif : Dscam, qui, dans le système nerveux, peut engendrer 38.000 messages différents ! Ce sont les mammifères qui exploitent le mieux cette formidable machine à créer de la diversité. Chez l'homme, 95 % des jeunes sont épissés. Ce mécanisme semblant avoir accompagné l'évolution de la vie animale, le décrypter pourrait révéler comment l'homme a pu acquérir sa complexité. "Nous étudions les variations entre les codes de l'épissage de la souris et de l'homme : certaines pourraient expliquer les différences de sophistication d'organes aussi importants que le cerveau", prévoit le professeur Brendan Frey, chef de l'équipe canadienne décrypteuse du code de l'épissage alternatif.
 UN CODE POUR DÉCOUVRIR L'ORIGINE DES MALADIES
UN CODE POUR DÉCOUVRIR L'ORIGINE DES MALADIES
Cancers du sein, dystrophie musculaire, poumons envahis de mucus dans un cas de mucoviscidoses... Nombre de cancers et de maladies génétiques sont liées à des anomalies de l'épissage. "Connaître le code derrière l'épissage alternatif d'aider à la compréhension de certaines maladies", soulignent France Denoeud et Kamel Jabbari, du Génoscope. En effet, "nombre de cancers et de maladies génétiques sont liées à des anomalies de l'épissage", précise Joëlle Marie, spécialiste de ce mécanisme à l'Inserm. Il était facile d'admettre qu'une mutation survenant dans un gène puisse induire une erreur dans la protéine qu'il code, et donc causer une maladie (myopathie, etc.). Or, l'information portée par un gène n'est pas conservée in extenso dans les messages qu'il engendre : on pourrait penser que seules les mutations modifiant les fragments du message génétique utilisés pour former la protéine auraient une incidence. Mais ce n'est pas le cas : une mutation dans un fragment non conservé peut aussi altérer la bonne formation des protéines... "En fait, ces mutations peuvent toucher des séquences importantes pour la régulation de l'épissage, qui conditionne quels fragments du message vont être conservés ou pas", explique la directrice de recherche de l'Inserm. Des larges pans du message génétique pouvaient donc être oubliés ou ajouter à tort, provoquant des bouleversements dans la protéine finale. Les travaux canadiens, en aidant à prédire dans un message génétique où sont les "mots codes" importants pour sa bonne mise en forme, permettent de comprendre les effets jusqu'ici injustifiés de certaines mutations et de trouver une origine à des affections encore inexpliquées, telles que certaines mucoviscidoses ou des cancers du sein ou de la prostate.
E.R. - SCIENCE & VIE > Octobre > 2010 |