La Molécule d'ADN |
L'Expression des Gènes |

T.C. - ÇA M'INTÉRESSE Questions N°26 > Mai-Juillet > 2019 |
Après le Code ADN à 6 Lettres, voici celui à 8 Lettres |

E.A. - SCIENCE & VIE N°1219 > Avril > 2019 |
Une autre Forme d'ADN existe dans nos Cellules |

J.-B.V. - SCIENCE & VIE N°1210 > Juillet > 2018 |
Des Séquences d'ADN pas si Inutiles |

A.G. - POUR LA SCIENCE N°485 > Mars > 2018 |
Code du Vivant : l'ADN a 6 Bases |
 La structure de l'ADN avec ses 4 bases ATGC semblait gravée dans le marbre. Sauf qu'après une 5ème base découverte chez les mammifères il y a plusieurs années, une 6ème vient d'être repérée. Aude Rambaud a décrypté ce nouvel alphabet du vivant.
La structure de l'ADN avec ses 4 bases ATGC semblait gravée dans le marbre. Sauf qu'après une 5ème base découverte chez les mammifères il y a plusieurs années, une 6ème vient d'être repérée. Aude Rambaud a décrypté ce nouvel alphabet du vivant.
Ah... l'ADN ! Chercher a décrire cette hélice délicate qui porte l'information génétique dans chaque cellule, c'est un peu comme entrer dans la Vallée des rois en Égypte. Il y a toujours un secret dissimulé, une fonction suspecte, des rebondissements. Et, au bout du compte, un fil plus complexe à dénouer que ce que les livres ne nous enseignaient.
Prenez la composition même de la molécule d'ADN. L'histoire semblait simple : ce long brin est censé n'être constitué que d'un enchainement de quatre molécules - la cytosine (C), la guanine (G), la thymine (T) et l'adénine (A) - ces "bases" s'assemblant tels les barreaux d'une échelle avec les bases d'un autre brin pour former la fameuse double hélice. ACCTTGAGAA... Même si ces textes génétiques longs de milliards de bases restent délicats à interprêter, au moins leur écriture n'était-elle pas trop difficile à apprendre : juste 4 lettres pour décrire les séquences génétiques de toutes les formes de vie terrestre. Un code de la vie à 4 signes : la biologie, pour une fois, faisait dans l'épure. Oui, mais voila... Dans les années 1980, des chercheurs ont identifié chez des mammifères, dont l'homme, une variante très fréquente de la cytosine : la 5-méthylcytosine ou 5mC. Cette "5e base" devait se révéler particulièrement importante pour le développement embryonnaire, et se trouvait impliquée dans la survenue de cancers. Mais la découverte semblait alors devoir être rangée au rayon des exceptions.
 UNE NOUVELLE SÉRIE ? Sauf qu'une 6e base, identifiée chez des bactéries, vient d'être aussi découverte chez plusieurs espèces animales. Cette fois, c'est une variante de l'adénine, la 6-méthyladénine (ou 6mA). Et au fond, il pourrait bien s'agir du début d'une nouvelle série... Certains chercheurs parlent ainsi d'une 7e base avec la 5-formylcytosine, et même d'une 8e base avec la 5-carboxylcytosine. Cette découverte, due à de nouvelles techniques d'analyse moléculaire hypersensibles détectant une base unique parmi des milliers sur le génome, nous oblige à ravoir nos leçons élémentaires de génétique.
UNE NOUVELLE SÉRIE ? Sauf qu'une 6e base, identifiée chez des bactéries, vient d'être aussi découverte chez plusieurs espèces animales. Cette fois, c'est une variante de l'adénine, la 6-méthyladénine (ou 6mA). Et au fond, il pourrait bien s'agir du début d'une nouvelle série... Certains chercheurs parlent ainsi d'une 7e base avec la 5-formylcytosine, et même d'une 8e base avec la 5-carboxylcytosine. Cette découverte, due à de nouvelles techniques d'analyse moléculaire hypersensibles détectant une base unique parmi des milliers sur le génome, nous oblige à ravoir nos leçons élémentaires de génétique.
À l'instar de la 5e base, cette 6e n'est pas complètement originale car il s'agit en fait d'une adénine modifiée portant un groupement chimique méthyl supplémentaire (ci-contre ->). Il n'en reste pas moins que son titre de "base supplémentaire" n'est pas usurpé. Trois études publiées simultanément viennent en effet de montrer que cette base semble bel et bien stable dans l'ADN, conservée au cours des divisions cellulaires, transmise de génération en génération et dotée de fonctions de régulation génique précises. En pratique, une équipe américaine de Harvard vient de démontrer que la base 6mA est présente chez le ver C. elegans où associée à des phénomènes de régulation génétique, elle reste stable avec les générations.
Une seconde équipe américaine (université de Chicago) a précisé chez l'algue verte Chlamydomonas les sites préférentiels de cette base dans les zones d'activation des gènes, ce qui suggère qu'elle a un rôle dans l'organisation du génome. Enfin, une équipe chinoise a montré que la base 6mA est présente en petite quantité chez la mouche drosophile, dans des zones particulièrement actives lors du développement précoce, ce qui suggère un rôle pendant l'embryogénèse. Autant dire que l'implication de cette base dans la régulation de l'information génétique ne laisse guère de place au doute !
UN ADN PLUS SUBTIL : "Les mécanismes permettant d'obtenir cette base ou de l'éliminer sont conservés au cours de l'évolution, mais ses fonctions semblent variables chez les différents organismes, note Bernard Dujon, généticien à l'Institut Pasteur et membre de l'Académie des sciences. Cela n'a rien d'étonnant. Chaque organisme a pu détourner la machinerie d'origine pour utiliser cette base selon ses besoins. Il est tout à fait probable qu'on la retrouve également chez l'homme, mais là encore, ses fonctions seront a priori différentes". Les biologistes doivent donc d'ores et déjà réapprendre à lire. "Cette découverte montre que la structure de l'ADN est bien plus subtile qu'on le croyait, analyse Thierry Forné, chercheur à l'Institut de génétique moléculaire de Montpellier (CNRS). Elle ouvre des perspectives nouvelles pour comprendre des mécanismes non encore élucidés, comme la façon dont sont régulées les séquences d'ADN mobiles dans le génome, ou la façon dont les cellules se différencient en tel ou tel type cellulaire".
Difficile pour l'instant d'en dire plus. "À ce stade, les travaux publiés, très descriptifs, ne détaillent pas de mécanisme de régulation et n'apportent pas encore d'informations intéressantes sur le plan biologique", reconnait Christophe Antoniewski, chercheur au CNRS, spécialisé en génétique et épigénétique de la drosophile. Ils prouvent en revanche que les techniques modernes d'analyse moléculaire sont assez fines et performantes pour découvrir des bases rares, ce qui est un bon point de départ et donne envie de connaître la suite !" Il est à parier que, dans les années à venir, d'autres bases seront ainsi découvertes. "Visiblement, on en trouvera quelques-unes chez l'homme, confirme Thierry Forné. Et à l'échelle de l'ensemble du vivant, il est fort possible que cette diversité soit bien plus grande qu'on ne le pensait. D'autant que de nombreux organismes n'ont pas encore été étudiés". Il ne faut cependant pas se tromper : "D'autres facteurs de régulation plus massifs, qui sont actuellement à l'étude, fourniront probablement plus de renseignements que la présence d'une base rare dans le génome", prévient Christophe Antoniewski, qui évoque l'importance du repliement du génome en 3 dimensions dans le noyau, ou le rôle des ARN, molécules intermédiaires entre gène et protéine. Reste que ces nouvelles bases sont des clés supplémentaires à ajouter au trousseau destiné à ouvrir les portes du génome. Et elles prouvent que dans la Vallée des rois, les histoires ne sont jamais simples.
Quand l'homme invente de nouvel les bases. L'année dernière, l'équipe du biologiste américain Floyd Romesberg annonçait une révolution. Elle avait réussi à introduire deux bases artificielles dans le génome d'un organisme vivant, la bactérie E. coli. Un nouveau code génétique à deux lettres supplémentaires, qui n'a pas empêché les bactéries de se multiplier. Leur curieuse descendance, dotée de cet ADN hors normes, est une forme de vie à la fois naturelle et artificielle. Le défi relevé par les chercheurs est maintenant de réussir à traduire ces nouvelles bases en acides aminés synthétiques, qui pourraient conférer aux protéines des fonctions qui n'existent pas dans le monde vivant, comme la sensibilité au magnétisme. N.P.-S. |
Aude Rambaud - SCIENCE & VIE N°1175 > Août > 2015 |
La Double Hélice n'est qu'une des Formes de l'ADN |
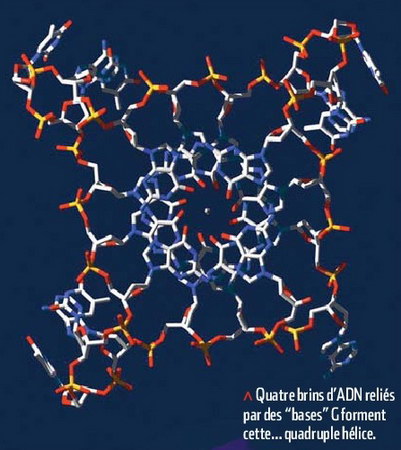 Près de soixante ans après la découverte de la structure en double hélice de l'ADN, une équipe de l'université anglaise de Cambridge, dirigée par Shankar Balasubramanian, a montré que les chromosomes humains contiennent aussi des portions d'ADN sous forme de quadruple hélice !
Près de soixante ans après la découverte de la structure en double hélice de l'ADN, une équipe de l'université anglaise de Cambridge, dirigée par Shankar Balasubramanian, a montré que les chromosomes humains contiennent aussi des portions d'ADN sous forme de quadruple hélice !
La double hélice classique apparaît comme une échelle vrillée, dont les montants (les deux brins d'ADN) sont reliés par des paires de "bases" (les briques de l'ADN, désignées par leurs initiales A, T, G et C) qui forment les barreaux. La quadruple hélice peut, elle, être représentée comme une étagère dont les quatre pieds seraient autant de brins d'ADN portant une suite de bases G - quatre G se faisant face constituant les plateaux. C'est une abondance de bases G (des molécules de guanine) qui permet le repliement de l'ADN en quadruple hélice. Déjà observées in vitro, ces structures ont cette fois été repérées le long des chromosomes, jusqu'à leurs extrémités. Elles se forment en particulier dans les cellules qui se divisent rapidement, comme les cellules tumorales, et pourraient intervenir dans la régulation de la multiplication cellulaire. Ce qui en ferait des cibles potentielles pour des traitements anticancéreux.
V.E. - SCIENCE & VIE > Avril > 2013 |
ADN : une Molécule aux Propriétés Exceptionnelles |
 Forme, structure, compacité, flexibilité, stabilité... Les propriétés de l'acide désoxyribonucléique sont uniques, et chacune concourt à protéger et à transmettre fidèlement le message du vivant. Décryptage en 9 points.
Forme, structure, compacité, flexibilité, stabilité... Les propriétés de l'acide désoxyribonucléique sont uniques, et chacune concourt à protéger et à transmettre fidèlement le message du vivant. Décryptage en 9 points.
UNE FORME EN DOUBLE HÉLICE : Adénine (A), thymine (T), cytosine (C) et guanine (G) : en s'associant chacune avec un sucre (le désoxyribose) et un groupement phosphate, ces quatre bases azotées forment des nucléotides capables de s'accrocher les uns aux autres pour tricoter un brin de longueur indéfinie. Mais ces quatre bases peuvent en outre se lier deux par deux (A avec T, C avec G), via des liaisons hydrogènes en couples complémentaires de longueur égale. Résultat ? Telle une fermeture éclair, deux brins s'accolent, d'une paire de bases à l'autre, en prenant la forme caractéristique d'une double hélice.
DES STRUCTURES MULTIPLES : Le principe d'une double hélice permet différentes formes. La plus fréquente est de loin l'ADN-B, une double hélice tournant vers la droite et effectuant un tour complet tous les 10 nucléotides (chaque paire de bases étant décalée de la précédente d'un angle de 36°). Mais d'autres formes existent, comme l'ADN-A, plus court et plus large, qu'on retrouve dans les milieux déshydratés, ou l'ADN-Z, tournant alternativement vers la gauche et la droite et effectuant ainsi des zigzags. Des biochimistes ont même obtenu, par étirement et torsion, un ADN-P dans lequel les bases azotées se retrouvent à l'extérieur de la double hélice. La double hélice d'ADN peut en outre, en particulier chez les virus et les bactéries, décrire un cercle et n'avoir, dès lors, aucune extrémité.
 UN CODE QUASI UNIVERSEL : Les quatre bases azotées ne servent pas qu'à construire une double hélice. Elles constituent l'alphabet à partir duquel est écrite l'information qui constitue notre hérédité. Toutes les protéines sont bâties à partir d'acides aminés, selon une séquence codée par la succession des différentes bases. Une succession a 3 bases forme un codon. Il y en a donc 4³ = 64 possibles, parmi lesquels, 61 désignent un acide aminé, les 3 autres constituant un signal de terminaison. Comme il n'existe que 20 acides aminés dans la nature, il y a plus de codon que d'acides aminés. Le code est donc redondant : plusieurs combinaisons codent pour un même acide aminé. Mais il est quasi universel : d'une espèce à l'autre, chaque triplet code, en général, le même acide aminé permettant des interactions entre génomes.
UN CODE QUASI UNIVERSEL : Les quatre bases azotées ne servent pas qu'à construire une double hélice. Elles constituent l'alphabet à partir duquel est écrite l'information qui constitue notre hérédité. Toutes les protéines sont bâties à partir d'acides aminés, selon une séquence codée par la succession des différentes bases. Une succession a 3 bases forme un codon. Il y en a donc 4³ = 64 possibles, parmi lesquels, 61 désignent un acide aminé, les 3 autres constituant un signal de terminaison. Comme il n'existe que 20 acides aminés dans la nature, il y a plus de codon que d'acides aminés. Le code est donc redondant : plusieurs combinaisons codent pour un même acide aminé. Mais il est quasi universel : d'une espèce à l'autre, chaque triplet code, en général, le même acide aminé permettant des interactions entre génomes.
UNE ÉNORME CAPACITÉ DE STOCKAGE : La très grande taille de la molécule d'ADN permet de stocker une quantité très importante d'informations : de mille (pour le génome le plus court) à plus de 500 milliards de paires de bases, pour le génome le plus long jamais observé, celui d'une... amibe (Amoebia dubia). Il n'y a donc pas de corrélation directe entre la taille du génome et la complexité de l'organisme, le génome pouvant s'accroître par duplication de certaines séquences ou intégration d'ADN étranger. Celui de l'espèce humaine est néanmoins d'une taille respectable, puisqu'il contient (dans les gamètes) près de 3,2 milliards de paires de bases.
 UNE STABILITÉ MAXIMALE : L'ADN est particulièrement stable. Car la double hélice renferme un grand nombre de liaisons faibles (liaisons hydrogène et interactions entre nuages électroniques) disposées de telle sorte que la plupart ne peuvent rompre sans que soient brisées simultanément de nombreuses autres liaisons. Ce qui, pour y parvenir, exige une énergie considérable. Les liaisons accidentellement rompues ont donc plutôt tendance à se reformer spontanément. D'autant que les bases azotées qui sont à l'intérieur de la double hélice sont hydrophobes (elles fuient l'eau). Or, toute rupture locale de la double hélice les mettrait en contact avec les nombreuses molécules d'eau qui, dans la cellule, entourent l'ADN. Ce qui est chimiquement impossible à moins d'apporter, là encore, une énergie suffisante pour vaincre la répulsion chimique entre ces bases et l'eau.
UNE STABILITÉ MAXIMALE : L'ADN est particulièrement stable. Car la double hélice renferme un grand nombre de liaisons faibles (liaisons hydrogène et interactions entre nuages électroniques) disposées de telle sorte que la plupart ne peuvent rompre sans que soient brisées simultanément de nombreuses autres liaisons. Ce qui, pour y parvenir, exige une énergie considérable. Les liaisons accidentellement rompues ont donc plutôt tendance à se reformer spontanément. D'autant que les bases azotées qui sont à l'intérieur de la double hélice sont hydrophobes (elles fuient l'eau). Or, toute rupture locale de la double hélice les mettrait en contact avec les nombreuses molécules d'eau qui, dans la cellule, entourent l'ADN. Ce qui est chimiquement impossible à moins d'apporter, là encore, une énergie suffisante pour vaincre la répulsion chimique entre ces bases et l'eau.
UNE COMPLEXITÉ CROISSANTE : La majeure partie du génome, chez les êtres pluricellulaires, ne sert pas à coder des acides aminés. À quoi sert cet ADN hâtivement qualifié "d'ADN poubelle" ? La suppression de certaines portions entraîne des anomalies de développement. Elles réguleraient donc l'expression des gènes. D'autres - les pseudogènes - sont manifestement d'anciens gènes ayant perdu leur fonction au cours de l'évolution. Quant au reste, il est constitué pour l'essentiel d'éléments répétés de multiples fois, et dont la fonction est, pour l'essentiel, non connue pour l'instant. Ainsi, le séquençage complet du génome humain a révélé un nombre relativement faible et le gènes codant une protéine : de l'ordre de 20.000 (chacun comprenant en moyenne 27.000 paires de bases, dont 1300 - soit 5 % à peine - concrètement traduites en protéine). 20.000 autres gènes sont non codants. Quant à l'ADN non génique, il représente au moins 50 % du génome humain.
UNE GRANDE FLEXIBILITÉ : La molécule d'ADN est suffisamment souple pour s'adapter aux différentes torsions de la double hélice sur elle-même. Quant aux bases azotées (A, T, C, G) qui se trouvent à l'intérieur, elles peuvent même pivoter, pour sortir momentanément de la double hélice. Une opération peu gourmande en énergie, dès lors qu'une seule base est retournée à la fois, et qui permet à certaines enzymes de réparer les bases endommagés qui font ainsi saillie.
UNE RÉPLICATION FACILE : A avec T, C avec G... chaque base ayant sa base complémentaire, dupliquer un brin d'ADN repose sur un principe simple : il suffit de séparer les deux brins et de reconstituer avec chacun d'eux une nouvelle double hélice, strictement identique à la première, en synthétisant le brin complémentaire.
UNE COMPACITÉ EXTRÊME : L'ADN est une chaîne extrêmement longue : chaque cellule humaine en contient 1,8 mètre, dans un noyau qui ne fait pourtant que... 6 micromètres de diamètre. Comment est-ce possible ? La double hélice s'enroule d'abord autour de molécules appelées histones, chaque boucle constituant un nucléosome. Ce premier procédé permet, à lui seul, d'obtenir une molécule d'ADN six fois plus condensée. Ces nucléosomes s'enroulent à leur tour pour former un solénoïde comportant 6 nucléosomes par tour de spire, ce qui permet de condenser encore d'un facteur 40. Cette fibre solénoïde forme enfin des "superboules", qui permettent, cette fois, de condenser encore mille fois plus l'ADN.
SCIENCE & VIE > Février > 2013 |
Peut-on Avoir le Même ADN sans Être Jumeau ? |
 Même l'ADN des jumeaux n'est pas identique : toutes les cellules d'un individu n'apportent pas tout à fait la même séquence.
Même l'ADN des jumeaux n'est pas identique : toutes les cellules d'un individu n'apportent pas tout à fait la même séquence.
Oui, en théorie. Mais dans la réalité, la probabilité est infime. La molécule d'ADN lovée au cour de nos cellules comporte 3 milliards de paires de base, chacune de ses paires étant formée de 2 éléments parmi 4 (adénine et guanine, cytosine et thymine). La probabilité de rencontrer de séquences d'ADN identiques est donc de 1 chance sur 46.000.000.000 (un nombre si proche de zéro que notre cerveau ne peut se le représenter).
Mais ce calcul ne tient pas compte du fait que l'ADN des humains est en fait identique à 99,9 %. La différence réside donc dans le 0,1 % restant, qui ne représente plus que 6 millions de bases. Ce qui donne alors une probabilité de trouver deux ADN identiques deux une chance sur 46.000.000.000. Ce qui, concrètement, reste équivalent à zéro. Mais il faudrait tenir aussi compte de ce que, chez un même individu, toutes les cellules ne portent pas exactement la même séquence d'ADN : quelques mutations ponctuelles et sans effets peuvent introduire des différences. Même ADN des jumeaux n'est pas parfaitement identique !
M.Cy. - SCIENCE & VIE > Février > 2011 |